Extended Tofts model#
Show code cell source
# import statements
import itertools
import os
import numpy as np
from matplotlib import pyplot as plt
import csv
import pandas as pd
import seaborn as sns
from plotting_results_nb import plot_bland_altman, bland_altman_statistics, make_catplot
import json
from pathlib import Path
Test data#
Digital reference object of the brain from Bosca et al. 2016.
Test case labels: test_vox_T{tumour voxel number}_{SNR},e.g. test_vox_T1_30 Selected voxels:
datVIF=alldata[108,121,6,:]
datT1=alldata[121,87,6,:] –> tumour voxel 1
datT2=alldata[156,105,6,:] –> tumour voxel 2
datT3=alldata[139,93,6,:] –> tumour voxel 3
SNR was added to obtain data at different SNR (20, 30, 50 and 100). A delayed version of the test data was created by shifting the time curves with 5 time points. This data is labeled as ‘delayed’ and only used with the models that allow the fitting of a delay.
The DRO data are signal values, which were converted to concentration curves using dce_to_r1eff from welcheb/pydcemri from David S. Smith
Input and reference values were found from the accompanying pdf document, which describes the values per voxel.
T1 blood of 1440 ms
T1 tissue of 1084 for white matter and 1820 for grey matter, 1000 for T1-T3
TR=5 ms
FA=30
Hct=0.45
Tolerances
\(v_e\): a_tol=0.05, r_tol=0, start=0.2, bounds=(0,1)
\(v_p\): a_tol=0.025, r_tol=0, start=0.01, bounds=(0,1)
\(K^{trans}\): a_tol=0.005, r_tol=0.1, start=0.6, bounds=(0,5), units [/min]
delay: a_tol=0.5, r_tol=0, start=0, bounds=(-10,10), units [s]
Source: Bosca, Ryan J., and Edward F. Jackson. “Creating an anthropomorphic digital MR phantom—an extensible tool for comparing and evaluating quantitative imaging algorithms.” Physics in Medicine & Biology 61.2 (2016): 974.
Visualize test data#
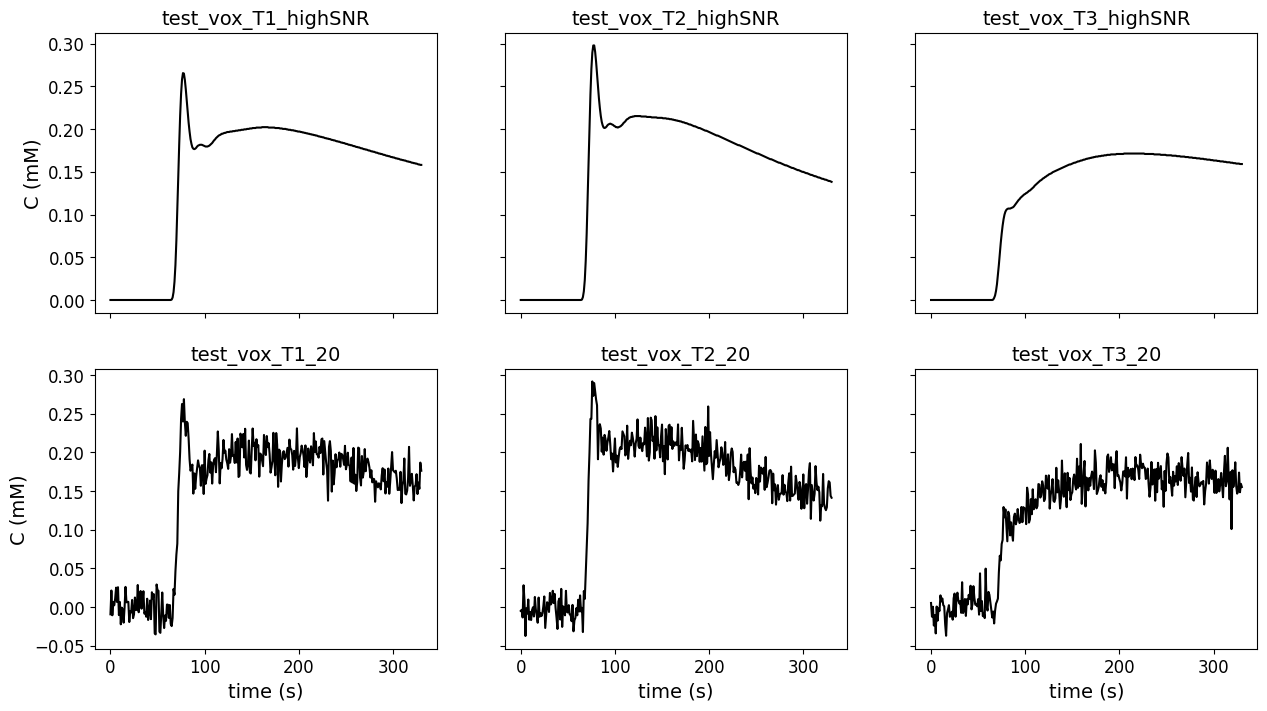
To get an impression of the test data that was used for the extended Tofts model, below we show the concentration time curves that were the input for the models. Here we show the data from high SNR from the original (first row) DRO and lowest SNR (SNR = 20; second row).
#plot test data
filename = ('../test/DCEmodels/data/dce_DRO_data_extended_tofts.csv')
# read from CSV to pandas
df1 = pd.read_csv(filename)
fig, ax = plt.subplots(2, 3, sharex='col', sharey='row', figsize=(15,8))
for currentvoxel in range(3):
labelname = 'test_vox_T' + str(currentvoxel+1) + '_highSNR'
testdata = df1[(df1['label']==labelname)]
t = testdata['t'].to_numpy()
t = np.fromstring(t[0], dtype=float, sep=' ')
c = testdata['C'].to_numpy()
c = np.fromstring(c[0], dtype=float, sep=' ')
ax[0,currentvoxel].plot(t, c, color='black', label='highSNR')
ax[0,currentvoxel].set_title(labelname, fontsize=14)
if currentvoxel ==0:
ax[0,currentvoxel].set_ylabel('C (mM)', fontsize=14)
ax[0,currentvoxel].tick_params(axis='x', labelsize=12)
ax[0,currentvoxel].tick_params(axis='y', labelsize=12)
labelname = 'test_vox_T' + str(currentvoxel+1) + '_20'
testdata = df1[(df1['label']==labelname)]
t = testdata['t'].to_numpy()
t = np.fromstring(t[0], dtype=float, sep=' ')
c = testdata['C'].to_numpy()
c = np.fromstring(c[0], dtype=float, sep=' ')
ax[1,currentvoxel].set_title(labelname, fontsize=14)
ax[1,currentvoxel].plot(t, c, color='black', label='SNR 20')
ax[1,currentvoxel].set_xlabel('time (s)', fontsize=14)
if currentvoxel ==0:
ax[1,currentvoxel].set_ylabel('C (mM)', fontsize=14)
ax[1,currentvoxel].tick_params(axis='x', labelsize=12)
ax[1,currentvoxel].tick_params(axis='y', labelsize=12)
Import data#
Import the csv files with test results. The source data are labelled and the difference between measured and reference values was calculated.
# Load the meta data
meta = json.load(open("../test/results-meta.json"))
# Loop over each entry and collect the dataframe
df = []
for entry in meta:
if (entry['category'] == 'DCEmodels') & (entry['method'] == 'etofts') :
fpath, fname, category, method, author = entry.values()
df_entry = pd.read_csv(Path(fpath, fname)).assign(author=author)
df.append(df_entry)
# Concat all entries
df = pd.concat(df)
# split delayed and non-delayed data
df['delay'] = df['label'].str.contains('_delayed')
# label data source
df['source']=''
df.loc[df['label'].str.contains('highSNR'),'source']='high SNR'
df.loc[df['label'].str.contains('_20'),'source']='SNR 20'
df.loc[df['label'].str.contains('_30'),'source']='SNR 30'
df.loc[df['label'].str.contains('_50'),'source']='SNR 50'
df.loc[df['label'].str.contains('_100'),'source']='SNR 100'
# label voxels
df['voxel']=''
df.loc[df['label'].str.contains('test_vox_T1'),'voxel']='voxel 1'
df.loc[df['label'].str.contains('test_vox_T2'),'voxel']='voxel 2'
df.loc[df['label'].str.contains('test_vox_T3'),'voxel']='voxel 3'
author_list = df.author.unique()
no_authors = len(author_list)
# calculate error between measured and reference values
df['error_Ktrans'] = df['Ktrans_meas'] - df['Ktrans_ref']
df['error_ve'] = df['ve_meas']- df['ve_ref']
df['error_vp'] = df['vp_meas']- df['vp_ref']
# tolerances
tolerances = { 'Ktrans': {'atol' : 0.005, 'rtol': 0.1 },'ve': {'atol':0.05, 'rtol':0}, 'vp': {'atol':0.025, 'rtol':0}}
Results#
Non-delayed data#
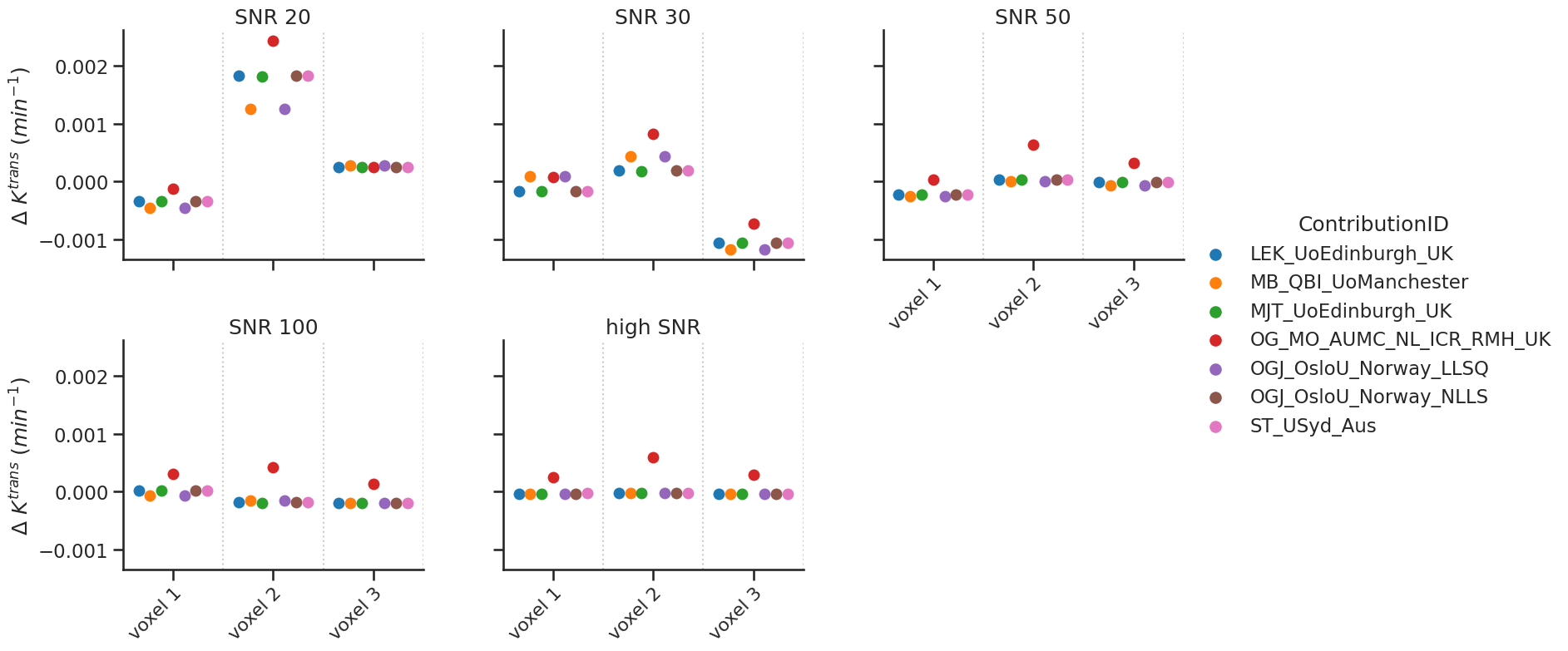
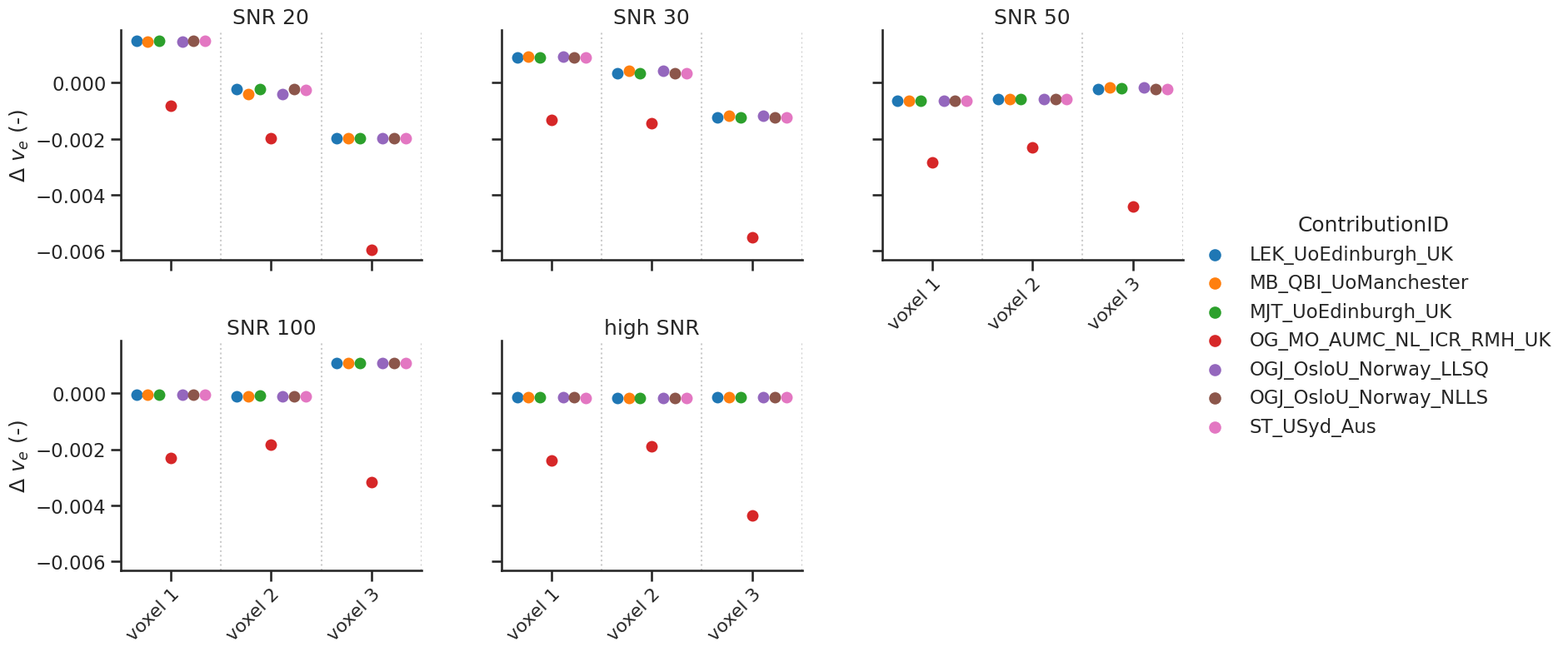
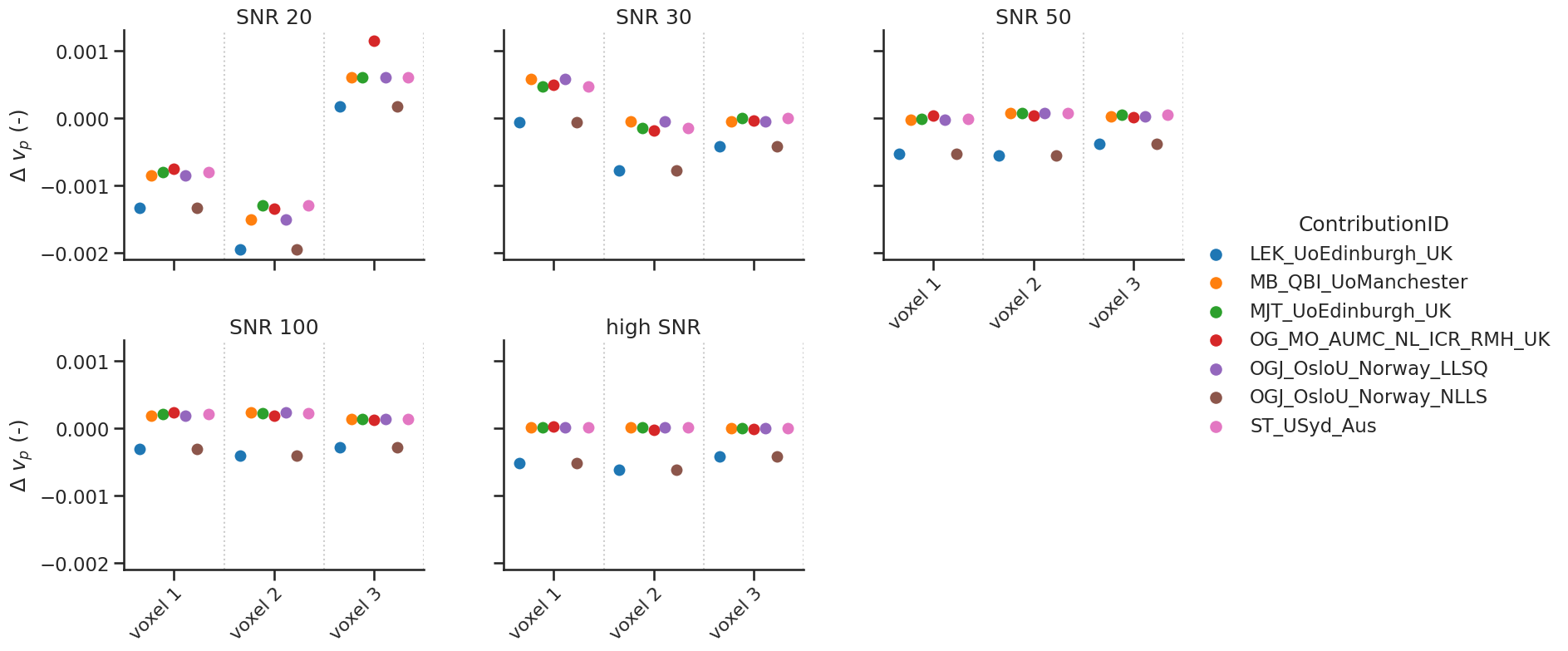
Some models allow the fit of a delay. For the tests with non-delayed data, the delay was fixed to 0. The data are shown with a categorial swarm plot, so for each text voxel separately to better appreciate the differences between contributions. Note that, the x-axis is not a continuous axis, but has a label per test voxel. To get an idea of the reference values per test case, the table below refers as a legend for the figure.
Note that, one author (OGJ_OsloU_NOR) provided two options to fit the model (LLSQ and NLLS). These were considered separate contributions.
df.head(n=3)[['voxel','Ktrans_ref','ve_ref', 'vp_ref']]
| voxel | Ktrans_ref | ve_ref | vp_ref | |
|---|---|---|---|---|
| 0 | voxel 1 | 0.063524 | 0.175212 | 0.021750 |
| 1 | voxel 2 | 0.075512 | 0.148789 | 0.024059 |
| 2 | voxel 3 | 0.050843 | 0.207023 | 0.004991 |
Show code cell source
# set-up styling for seaborn plots
#sns.set(font_scale=1.5)
#sns.set_style("whitegrid")
sns.set_style("ticks")
sns.set_context("talk", rc={"figure.figsize": (10,8)})
plotopts = {"hue":"author",
"col":"source",
"col_order":["SNR 20","SNR 30","SNR 50","SNR 100","high SNR"],
"dodge":True,
"col_wrap":3,
"s":100,
"height":4,
"aspect":1.25
}
# Instead of a regular bland-altman plot we opted for a catplot + swarm for these results.
# In this way we can appreciate the results of the different contributions per test case better.
# The downside is that the values of the test cases are not obvious.
# This might be something to improve upon at a later stage
make_catplot(x='voxel', y="error_Ktrans", data=df[~df['delay']],
ylabel="$\Delta$ $K^{trans}$ ($min^{-1}$)", **plotopts)
# same for ve
make_catplot(x='voxel', y="error_ve", data=df[~df['delay']],
ylabel="$\Delta$ $v_{e}$ (-)", **plotopts)
# same for vp
make_catplot(x='voxel', y="error_vp", data=df[~df['delay']],
ylabel="$\Delta$ $v_{p}$ (-)", **plotopts)
Bias results estimated \(K^{trans}\) values combined for all voxels (low and high SNR)
resultsBA = bland_altman_statistics(data=df[~df['delay']],par='error_Ktrans',grouptag='author')
print(resultsBA)
bias stdev LoA lower LoA upper
author
LEK_UoEdinburgh_UK 0.000003 0.000588 -0.001149 0.001154
MB_QBI_UoManchester -0.000026 0.000503 -0.001012 0.000960
MJT_UoEdinburgh_UK -0.000002 0.000587 -0.001152 0.001148
OGJ_OsloU_Norway_LLSQ -0.000026 0.000503 -0.001012 0.000960
OGJ_OsloU_Norway_NLLS 0.000003 0.000588 -0.001149 0.001154
OG_MO_AUMC_NL_ICR_RMH_UK 0.000380 0.000675 -0.000942 0.001702
ST_USyd_Aus 0.000004 0.000588 -0.001149 0.001156
Bias results estimated \(v_e\) values combined for all voxels (low and high SNR)
resultsBA = bland_altman_statistics(data=df[~df['delay']],par='error_ve',grouptag='author')
print(resultsBA)
bias stdev LoA lower LoA upper
author
LEK_UoEdinburgh_UK -0.000111 0.000865 -0.001807 0.001585
MB_QBI_UoManchester -0.000113 0.000869 -0.001815 0.001589
MJT_UoEdinburgh_UK -0.000105 0.000865 -0.001800 0.001590
OGJ_OsloU_Norway_LLSQ -0.000113 0.000869 -0.001815 0.001589
OGJ_OsloU_Norway_NLLS -0.000111 0.000865 -0.001807 0.001585
OG_MO_AUMC_NL_ICR_RMH_UK -0.002839 0.001547 -0.005871 0.000192
ST_USyd_Aus -0.000116 0.000865 -0.001812 0.001579
Bias results estimated \(v_p\) values combined for all voxels (low and high SNR)
resultsBA = bland_altman_statistics(data=df[~df['delay']],par='error_vp',grouptag='author')
print(resultsBA)
bias stdev LoA lower LoA upper
author
LEK_UoEdinburgh_UK -0.000561 0.000508 -0.001556 0.000434
MB_QBI_UoManchester -0.000041 0.000520 -0.001061 0.000979
MJT_UoEdinburgh_UK -0.000031 0.000468 -0.000947 0.000885
OGJ_OsloU_Norway_LLSQ -0.000041 0.000520 -0.001061 0.000979
OGJ_OsloU_Norway_NLLS -0.000561 0.000508 -0.001556 0.000434
OG_MO_AUMC_NL_ICR_RMH_UK -0.000003 0.000541 -0.001063 0.001056
ST_USyd_Aus -0.000032 0.000468 -0.000949 0.000884
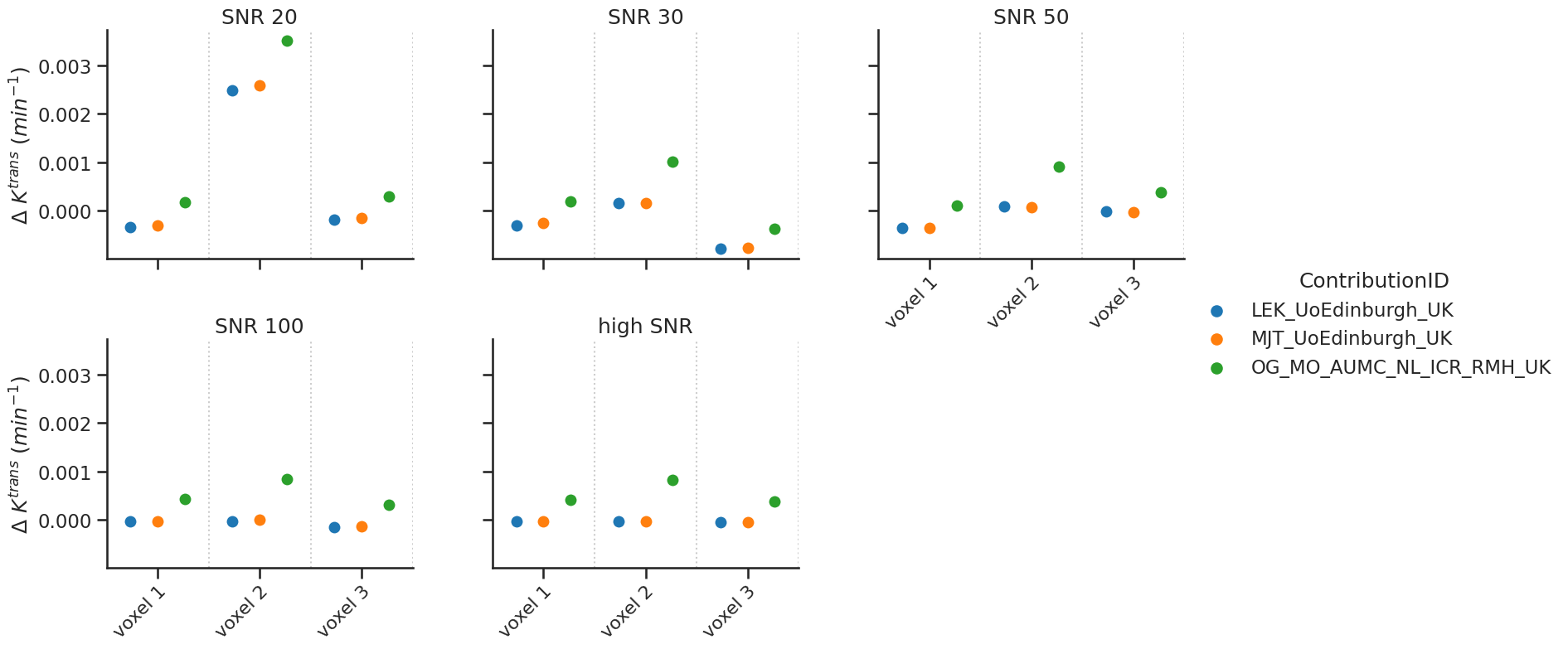
Delayed results#
Some contributions allowed the fitting of a delay. For those, additional tests with a delay were performed.
# Ktrans
make_catplot(x='voxel', y="error_Ktrans", data=df[df['delay']],
ylabel="$\Delta$ $K^{trans}$ ($min^{-1}$)", **plotopts)
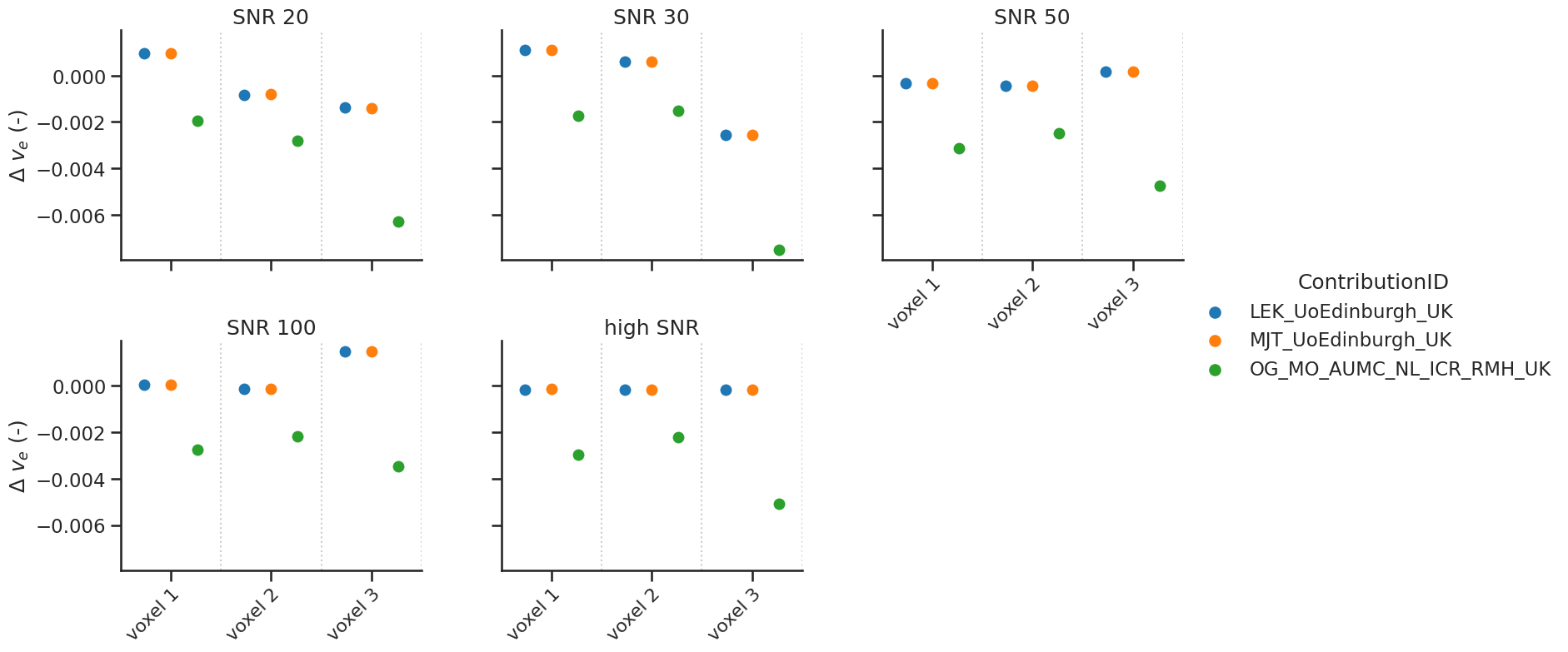
# same for ve
make_catplot(x='voxel', y="error_ve", data=df[df['delay']],
ylabel="$\Delta$ $v_{e}$ (-)", **plotopts)
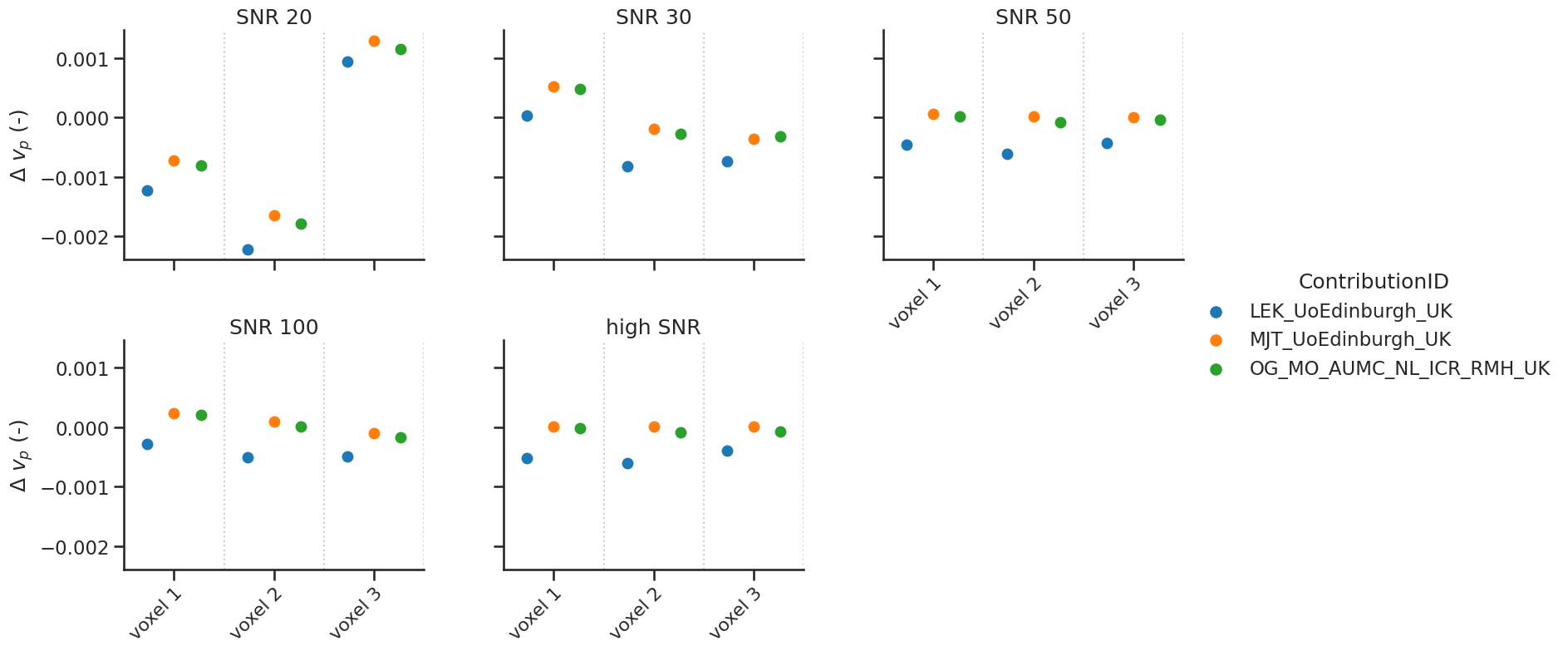
# same for vp
make_catplot(x='voxel', y="error_vp", data=df[df['delay']],
ylabel="$\Delta$ $v_{p}$ (-)", **plotopts)
Bias results estimated \(K^{trans}\) values combined for all voxels (low and high SNR)
resultsBA = bland_altman_statistics(data=df[df['delay']],par='error_Ktrans',grouptag='author')
print(resultsBA)
bias stdev LoA lower LoA upper
author
LEK_UoEdinburgh_UK 0.000026 0.000719 -0.001382 0.001435
MJT_UoEdinburgh_UK 0.000044 0.000738 -0.001402 0.001491
OG_MO_AUMC_NL_ICR_RMH_UK 0.000626 0.000876 -0.001091 0.002344
Bias results estimated \(v_e\) values combined for all voxels (low and high SNR)
resultsBA = bland_altman_statistics(data=df[df['delay']],par='error_ve',grouptag='author')
print(resultsBA)
bias stdev LoA lower LoA upper
author
LEK_UoEdinburgh_UK -0.000119 0.001005 -0.002088 0.001850
MJT_UoEdinburgh_UK -0.000116 0.001003 -0.002082 0.001850
OG_MO_AUMC_NL_ICR_RMH_UK -0.003392 0.001752 -0.006825 0.000042
Bias results estimated \(v_p\) values combined for all voxels (low and high SNR)
resultsBA = bland_altman_statistics(data=df[df['delay']],par='error_vp',grouptag='author')
print(resultsBA)
bias stdev LoA lower LoA upper
author
LEK_UoEdinburgh_UK -0.000556 0.000657 -0.001844 0.000731
MJT_UoEdinburgh_UK -0.000052 0.000621 -0.001269 0.001165
OG_MO_AUMC_NL_ICR_RMH_UK -0.000122 0.000624 -0.001344 0.001101
Notes#
Additional notes/remarks