Patlak Model#
Show code cell source
# import statements
import os
import numpy as np
from matplotlib import pyplot as plt
import csv
import pandas as pd
import seaborn as sns
from plotting_results_nb import plot_bland_altman, bland_altman_statistics, make_catplot
import json
from pathlib import Path
Test data#
Data summary: simulated Patlak model data
Source: Concentration-time data (n = 9) generated by M. Thrippleton using Matlab code at mjt320/DCE-functions
Detailed info:
Temporal resolution: 0.5 s
Acquisition time: 300 s
AIF: Parker function, starting at t=10s
Noise: SD = 0.02 mM
Arterial delay: none
Reference values: Reference values are the parameters used to generate the data. All combinations of \(v_p\) (0.1, 0.2, 0.5) and PS (0, 5, 15)*1e-2 per min are included. A delayed version of the test data was created by shifting the time curves with 5s. This data is labeled as ‘delayed’ and only used with the models that allow the fitting of a delay.
Citation: Code used in Manning et al., Magnetic Resonance in Medicine, 2021 https://doi.org/10.1002/mrm.28833 and Matlab code: mjt320/DCE-functions
Tolerances
\(v_p\): a_tol=0.025, r_tol=0, start=0.01, bounds=(0,1)
PS: a_tol=0.005, r_tol=0.1, start=0.6, bounds=(0,5), units [/min]
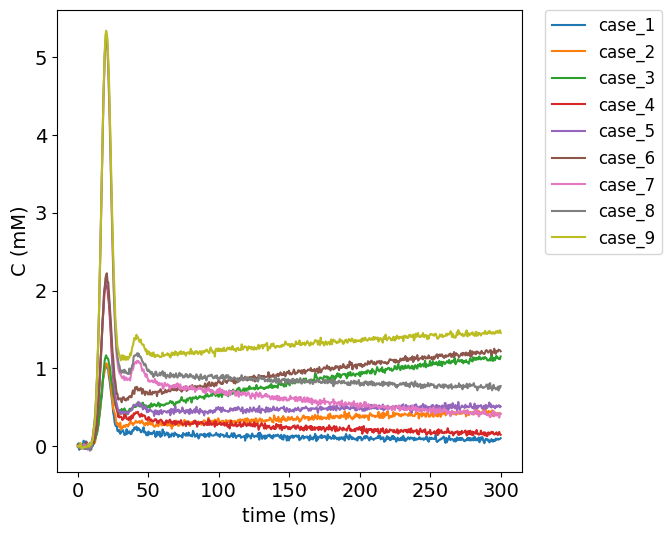
Visualize test data#
To get an impression of the test data, the concentration time curves of the test data are plotted below.
#plot test data
filename = ('../test/DCEmodels/data/patlak_sd_0.02_delay_0.csv')
# read from CSV to pandas
df1 = pd.read_csv(filename)
no_voxels = len(df1.label)
fig, ax = plt.subplots(1, 1, sharex='col', sharey='row', figsize=(6,6))
for currentvoxel in range(no_voxels):
labelname = 'case_' + str(currentvoxel+1)
testdata = df1[(df1['label']==labelname)]
t = testdata['t'].to_numpy()
t = np.fromstring(t[0], dtype=float, sep=' ')
c = testdata['C_t'].to_numpy()
c = np.fromstring(c[0], dtype=float, sep=' ')
ax.plot(t, c, label=labelname)
ax.set_ylabel('C (mM)', fontsize=14)
ax.set_xlabel('time (ms)', fontsize=14)
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0,fontsize=12);
plt.xticks(fontsize=14)
plt.yticks(fontsize=14);
Import data#
# Load the meta data
meta = json.load(open("../test/results-meta.json"))
# Loop over each entry and collect the dataframe
df = []
for entry in meta:
if (entry['category'] == 'DCEmodels') & (entry['method'] == 'patlak') :
fpath, fname, category, method, author = entry.values()
df_entry = pd.read_csv(Path(fpath, fname)).assign(author=author)
df.append(df_entry)
# Concat all entries
df = pd.concat(df)
author_list = df.author.unique()
no_authors = len(author_list)
# split delayed and non-delayed data
df['delay'] = df['label'].str.contains('_delayed')
# label voxels
# (there is probably a better way of doing this...)
df['voxel']=''
df.loc[df['label'].str.contains('case_1'),'voxel']='voxel 1'
df.loc[df['label'].str.contains('case_2'),'voxel']='voxel 2'
df.loc[df['label'].str.contains('case_3'),'voxel']='voxel 3'
df.loc[df['label'].str.contains('case_4'),'voxel']='voxel 4'
df.loc[df['label'].str.contains('case_5'),'voxel']='voxel 5'
df.loc[df['label'].str.contains('case_6'),'voxel']='voxel 6'
df.loc[df['label'].str.contains('case_7'),'voxel']='voxel 7'
df.loc[df['label'].str.contains('case_8'),'voxel']='voxel 8'
df.loc[df['label'].str.contains('case_9'),'voxel']='voxel 9'
# calculate error between measured and reference values
df['error_ps'] = df['ps_meas'] - df['ps_ref']
df['error_vp'] = df['vp_meas']- df['vp_ref']
# tolerances
tolerances = { 'ps': {'atol' : 0.005, 'rtol': 0.1 }, 'vp': {'atol':0.025, 'rtol':0}}
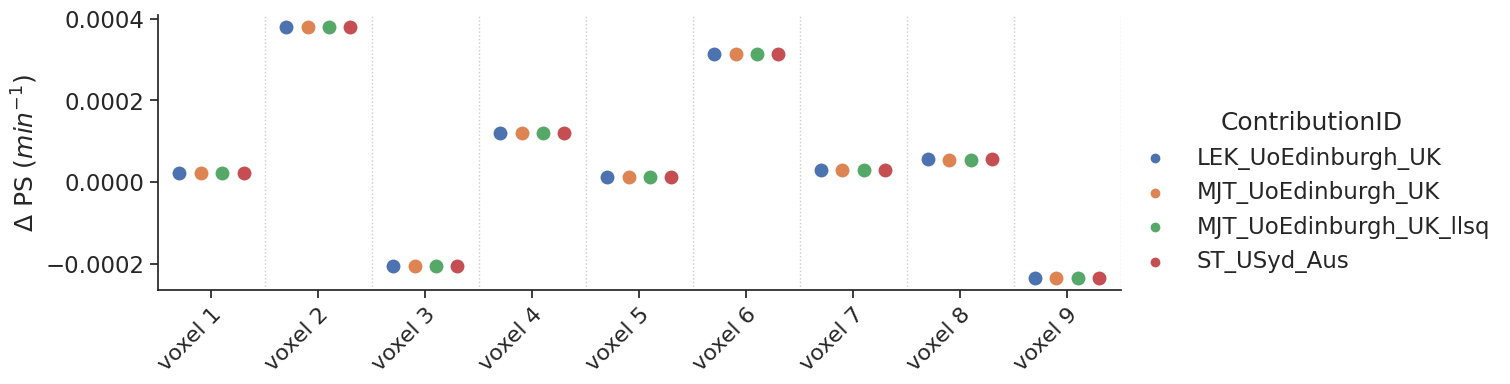
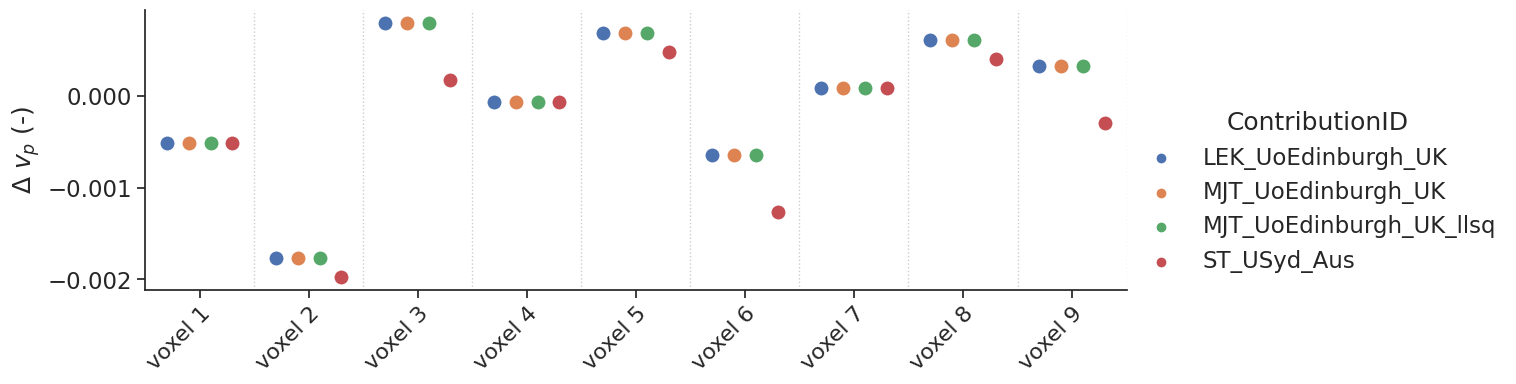
Results#
Non-delayed data#
Some models allow the fit of a delay. For the tests with non-delayed data, the delay was fixed to 0. The data are shown with a categorial swarm plot, so for each text voxel separately to better appreciate the differences between contributions. Note that, the x-axis is not a continuous axis, but has a label per test voxel. To get an idea of the reference values per test case, the table below refers as a legend for the figure.
For the contribtution MJT_UoEdingburgh_UK there are two contributions (NLLS and LLSQ fitting approach). The linear approach is labeled with an extra tag _LLSQ in the figures below.
df.head(n=9)[['voxel','ps_ref','vp_ref']]
| voxel | ps_ref | vp_ref | |
|---|---|---|---|
| 0 | voxel 1 | 0.00 | 0.1 |
| 1 | voxel 2 | 0.05 | 0.1 |
| 2 | voxel 3 | 0.15 | 0.1 |
| 3 | voxel 4 | 0.00 | 0.2 |
| 4 | voxel 5 | 0.05 | 0.2 |
| 5 | voxel 6 | 0.15 | 0.2 |
| 6 | voxel 7 | 0.00 | 0.5 |
| 7 | voxel 8 | 0.05 | 0.5 |
| 8 | voxel 9 | 0.15 | 0.5 |
# set-up styling for seaborn plots
sns.set(font_scale=1.5)
#sns.set_style("whitegrid")
sns.set_style("ticks")
plotopts = {"hue":"author",
"dodge":True,
"s":100,
"height":4,
"aspect":3
}
make_catplot(x='voxel', y="error_ps", data=df[~df['delay']],
ylabel="$\Delta$ PS ($min^{-1}$)", **plotopts)
make_catplot(x='voxel', y="error_vp", data=df[~df['delay']],
ylabel="$\Delta$ $v_p$ (-)", **plotopts)
Bias results estimated PS values combined for all voxels
resultsBA = bland_altman_statistics(data=df[~df['delay']],par='error_ps',grouptag='author')
print(resultsBA)
bias stdev LoA lower LoA upper
author
LEK_UoEdinburgh_UK 0.000054 0.000203 -0.000344 0.000453
MJT_UoEdinburgh_UK 0.000054 0.000203 -0.000344 0.000453
MJT_UoEdinburgh_UK_llsq 0.000054 0.000203 -0.000344 0.000453
ST_USyd_Aus 0.000054 0.000203 -0.000344 0.000453
Bias results estimated \(v_p\) values combined for all voxels
resultsBA = bland_altman_statistics(data=df[~df['delay']],par='error_vp',grouptag='author')
print(resultsBA)
bias stdev LoA lower LoA upper
author
LEK_UoEdinburgh_UK -0.000049 0.000821 -0.001658 0.001561
MJT_UoEdinburgh_UK -0.000049 0.000821 -0.001658 0.001561
MJT_UoEdinburgh_UK_llsq -0.000049 0.000821 -0.001658 0.001561
ST_USyd_Aus -0.000327 0.000817 -0.001928 0.001274
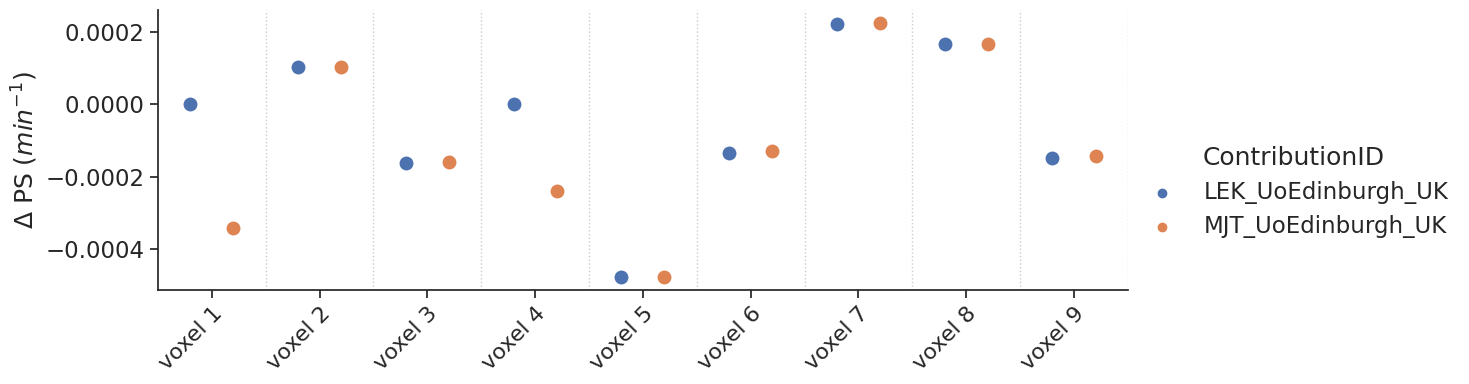
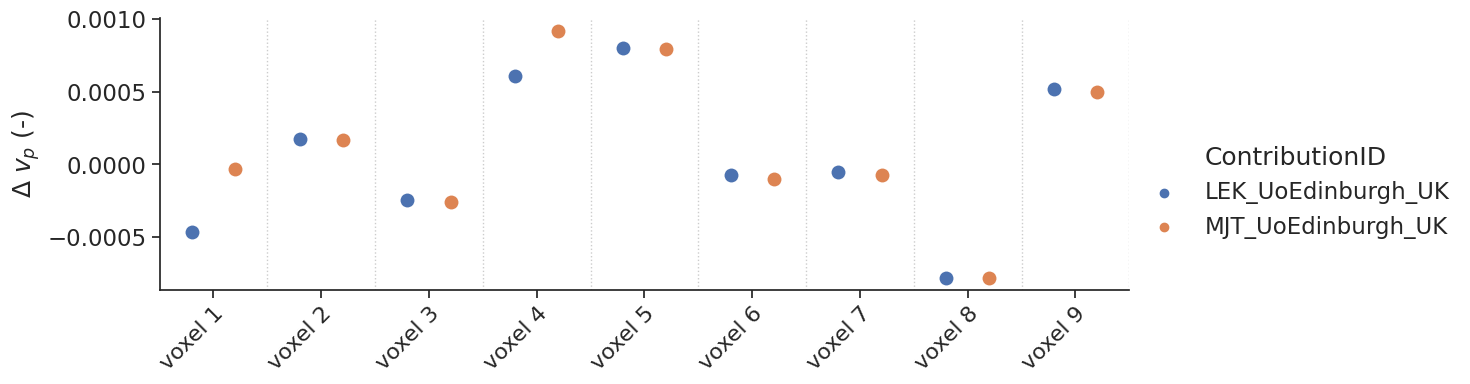
Delayed results#
Some contributions allowed the fitting of a delay. For those, additional tests with a delay were performed.
make_catplot(x='voxel', y="error_ps", data=df[df['delay']],
ylabel="$\Delta$ PS ($min^{-1}$)", **plotopts)
make_catplot(x='voxel', y="error_vp", data=df[df['delay']],
ylabel="$\Delta$ $v_p$ (-)", **plotopts)
Bias results estimated PS values combined for all voxels
resultsBA = bland_altman_statistics(data=df[df['delay']],par='error_ps',grouptag='author')
print(resultsBA)
bias stdev LoA lower LoA upper
author
LEK_UoEdinburgh_UK -0.000048 0.000213 -0.000465 0.000369
MJT_UoEdinburgh_UK -0.000111 0.000236 -0.000573 0.000351
Bias results estimated \(v_p\) values combined for all voxels
resultsBA = bland_altman_statistics(data=df[df['delay']],par='error_vp',grouptag='author')
print(resultsBA)
bias stdev LoA lower LoA upper
author
LEK_UoEdinburgh_UK 0.000054 0.000521 -0.000967 0.001075
MJT_UoEdinburgh_UK 0.000126 0.000537 -0.000926 0.001178
Notes#
Additional notes/remarks